The Simple AI Agent Playbook for Operators (2025)
TL;DR
- Agents shine when the path to the goal is uncertain and tool choice matters. Workflows win when steps are predictable.
- Ship a hub‑and‑spoke design (router → capability agents → tools → guardrails → observability → evals → human review).
- Expose actions consistently. Make pages LLM‑readable with stable headings, tables, dates, and copy‑paste code.
- Track outcomes like task success.
💡 If you’re a non‑developer, you can still ship: use Relay.app for event orchestration, n8n for visual automation, and Gumloop for data prep & structured prompts.
Why this playbook exists
Most teams don’t fail at models.
They fail at the surroundings: unclear scope, missing tools, no guardrails, and zero visibility into what the agent actually did.
This playbook is written for operators (product, support, growth) who need systems that resolve tasks on Monday morning and improve every week without a rewrite.
Who this is for
- Teams launching AI in support, sales, ops without a huge platform rebuild.
- Operators who prefer no‑code/low‑code and want to move fast with Relay.app, n8n, and Gumloop.
- Engineering teams who want a clear blueprint (LangGraph, OpenAI Agents SDK, AutoGen, CrewAI) and tight observability.
Top tools to operate this playbook
| Plan | Best For | Key Strength | Drawbacks | Pricing |
|---|---|---|---|---|
| Frameworks (Engineering-heavy) | ||||
| LangGraph | Stateful agent flows & recovery | Graph control, persistence, debugging | Initial graph design/learning curve | Open source |
| OpenAI Agents SDK | Lean production agent apps | Simple primitives, strong tool integration (MCP) | Vendor ecosystem alignment | Free SDK |
| AutoGen | Multi-agent collaboration patterns | Agent-to-agent messaging patterns | Python-centric; TS/JS lighter | Open source |
| CrewAI | Role-based “crews” (research/reporting) | Fast YAML config; quick to pilot | Less control for deep orchestration | Open source |
| Semantic Kernel | App copilots with skills/planners | Enterprise-friendly, model-agnostic | Planner tuning complexity | Open source |
| LlamaIndex Agents | RAG-centric agents & tools | Strong doc/RAG building blocks | Best when RAG is core to the app | OSS + hosted tiers |
| No-Code / Low-Code Builders | ||||
| Relay.app | Event orchestration & approvals | Human-in-the-loop steps, fast routing | Very complex branching may need code/n8n | SaaS tiers |
| n8n | Visual automation with APIs | Rich node library; self-host or cloud | More knobs to maintain | OSS + cloud tiers |
| Gumloop | Data prep & structured prompts | CSV/Sheets flows; repeatable enrichment | Deep custom tools via webhooks/APIs | SaaS tiers |
| Zapier | Quick SaaS-to-SaaS automations | Huge connector catalog | Limited complex logic | SaaS tiers |
| Make (Integromat) | Drag-and-drop workflows | Visual builder for SMB teams | Large scenarios can get brittle | SaaS tiers |
| Pipedream | Event-driven scripts & APIs | Serverless steps; quick glue code | Some JS required | Usage-based |
| Protocols & Specs (Tools / Access) | ||||
| MCP (Model Context Protocol) | Standard tool discovery & calls | Uniform tool interface across models | Ecosystem still maturing | Open spec |
| OpenAPI / JSON Schema | Tool arg/return contracts | Broad ecosystem; validation | Verbose; spec upkeep | Open spec |
| OAuth 2.0 | Secure app authorization | Standardized, widely supported | Setup complexity for newcomers | Open spec |
| Webhooks / Events | Triggering flows on changes | Simple, real-time orchestration | Retries/ordering & idempotency | Open patterns |
| GraphQL | Typed data access for tools | Precise queries; fewer roundtrips | N+1 & perf tuning required | Open spec |
| SAML SSO | Enterprise identity & access | Centralized authentication | Configuration overhead | Open standard |
| Knowledge, Retrieval & Search | ||||
| Pinecone | Managed vector search at scale | High performance; easy ops | Usage cost at large scale | Usage-based |
| Weaviate | Vector DB with hybrid search | Modules & filters; OSS + cloud | Self-host ops if on-prem | OSS + cloud tiers |
| Qdrant | Fast vector DB (Rust) | Great performance/footprint | Smaller ecosystem than ES/Algolia | OSS + cloud tiers |
| Elasticsearch / OpenSearch | Keyword + vector retrieval | Mature; enterprise features | Cluster complexity | OSS + cloud tiers |
| Algolia | Product/site search & discovery | Speed, typo-tolerance, analytics | Pricing at high traffic | Usage-based |
| Cohere Rerank | Reranking retrieved results | Improves precision of answers | Extra latency & API cost | Usage-based |
| Guardrails & Safety | ||||
| NeMo Guardrails | Policy, tone, and action gating | Programmable rules (Colang) | Learning curve to formalize rules | Open source |
| Azure AI Content Safety | Content moderation & safety | Enterprise integrations | Cloud-specific | Usage-based |
| AWS Guardrails for Bedrock | Policy controls for Bedrock apps | Native AWS governance | AWS-centric | Usage-based |
| Guardrails (Python library) | Response schemas & checks | JSON schema validation | Manual spec maintenance | Open source |
| Observability, Traces & Cost | ||||
| Langfuse | LLM traces, evals & metrics | Session-level visibility; dashboards | Self-host or subscribe | OSS + cloud tiers |
| Phoenix (Arize) | LLM observability & evals | Error analysis; dataset tools | Setup/infra if self-hosted | OSS |
| OpenTelemetry | Standardized tracing | Vendor-neutral spans/metrics | Instrumentation effort | Open spec |
| Evals & Testing | ||||
| TruLens | Feedback functions & evals | Groundedness/toxicity metrics | Requires labeled cases | Open source |
| Ragas | RAG answer quality | QA-style evals with citations | Labeling & dataset curation | Open source |
| OpenAI Evals | Benchmark harness & regressions | Reusable tasks; CI-friendly | Provider-specific tooling | Free SDK |
| promptfoo | Prompt testing in CI | Assertions & diffs for prompts | CLI/JSON config learning curve | Open source |
| Ingress, Channels & Handoff | ||||
| Twilio (SMS/Voice) | Phone/SMS support & outreach | Global reach; stable APIs | Telecom costs; compliance | Usage-based |
| Zendesk | Ticketing & support workflows | Handoff bot → human | Seat/licensing costs | SaaS |
| Intercom | Messenger, bots & ticketing | Unified chat + automation | Pricing at scale | SaaS |
| Freshdesk | Helpdesk for SMBs | Simple deployment | Fewer enterprise features | SaaS |
| Slack Platform | Internal agent interactions | Fast approvals/notifications | Less ideal for external users | SaaS |
| CRM & Sales Stack (Context & Routing) | ||||
| HubSpot | Inbound CRM & pipelines | SMB-friendly; quick integrations | Feature limits on lower tiers | SaaS |
| Salesforce | Enterprise CRM | Deep customization & ecosystem | Complexity & admin cost | Enterprise |
| Apollo / Cognism | Lead data & enrichment | Prospect discovery at scale | Data freshness varies | SaaS |
Agents vs workflows
Use a workflow when the steps are stable:
“Verify warranty → fetch order → issue RMA.” Deterministic flows = easy audits.
Add small model calls for classification and field extraction.
Use an agent when judgment and tool selection matter:
“Diagnose a billing discrepancy,” “Assemble a custom quote,” “Pick the right doc and escalate.” The agent plans, asks for missing context, and chooses tools in flight.
Quick tests
- If ≥80% of cases follow the same path, start with a workflow; embed AI inside steps.
- If paths vary or depend on context, start with an agent and add confirmation gates for risky actions.
- Avoid mega‑agents. Specialize by capability (i.e., Support resolutions, Sales qualification, Research synthesis, etc.).
Reference architecture (production‑ready)
- Ingress. Chat widget, web form, email, voice. Normalize input early (language, PII masking, IDs).
- Router. Decide workflow vs agent using a short rubric. Log the reason for debuggability.
- Capability agents. Focused responsibilities improve reasoning and prompts.
- Tools. Actions with typed args and safety flags. Tools are your contract with reality.
- Knowledge. Prefer structured stores and APIs. Use RAG for long‑tail questions.
- Guardrails. Enforce policy, tone, format, PII rules, and action gating for money/deletion.
- Observability. Trace prompts, tool calls, retrievals, cost, and latency.
- Evals. A small benchmark of real prompts and golden outcomes; run on every change.
- Human‑in‑the‑loop. For destructive or monetary actions, or when confidence is low.
Failure modes
- Silent tool failure masked by fancy text.
- RAG returns near‑duplicates; the agent hallucinates novelty.
- Latency spikes from oversized context windows or unnecessary tool calls.
Framework Options (Engineering‑heavy)
Use this to pick foundations if you have engineering support.
| Plan | Best For | Key Strength | Drawbacks | Pricing |
|---|---|---|---|---|
| LangGraph | Stateful agent flows | Recovery, persistence, debugging | Graph setup and learning curve | Open source |
| OpenAI Agents SDK | Lean agent apps | Tight integration with OpenAI APIs, MCP tooling | Vendor lock‑in risk | Free SDK |
| AutoGen | Multi‑agent collaboration | Patterns for agent‑to‑agent chat | Python‑heavy, less TS/JS support | Open source |
| CrewAI | Role‑based research/reporting | YAML crews, easy config | Limited orchestration depth | Open source |
No‑Code / Low‑Code Builders (Relay.app, n8n, Gumloop)
If you’re a less technical operator, you can still build good AI workflows.
This stack favors visual orchestration and structured prompts without writing much code.
| Plan | Best For | Key Strength | Drawbacks | Pricing |
|---|---|---|---|---|
| Relay.app | Event‑based orchestration between SaaS apps | Human‑in‑the‑loop steps, approvals, and routing; fast to deploy | Very advanced branching may need APIs or n8n complement | SaaS tiers; usage‑based |
| n8n | Visual automations with complex logic | Rich node library, self‑host or cloud; great for API chaining | More knobs = more to maintain; light scripting helps | Open source + cloud tiers |
| Gumloop | Data prep, table workflows, structured prompts | CSV/Sheets centric; excellent for repeatable research & enrichment | Deep custom tools require webhook/API steps in Relay/n8n | SaaS tiers |
How they fit together
- Trigger and approvals in Relay.app → heavy lifting and API choreography in n8n → Gumloop for clean data frames and structured prompts (import/export CSV or Google Sheets).
- You can add an LLM call at any step (summaries, categorization, extraction), and keep a human approval for money‑moving or customer‑facing actions.
Market Use Cases (Business‑level orchestration)
A simple way to explain agent deployments to execs and align budgets.
| Plan | Best For | Key Strength | Drawbacks | Pricing |
|---|---|---|---|---|
| Self‑service virtual agent | High‑volume FAQs and tasks | Fast answers, 24/7 coverage | Needs clear escalation to humans | Usage‑based |
| Agent assist copilot | Contact centers, help desks | Suggested replies, auto summaries | Requires training and workflow changes | Platform add‑on |
| Knowledge automation | Policy‑heavy or regulated teams | Consistent answers from vetted docs | Content upkeep and evaluation | SaaS per seat |
| Personalization layer | Web, app, and messaging journeys | Contextual offers and routing | Consent and governance burden | Tiered by MAU |
| End‑to‑end CX AI suite | Global enterprises scaling fast | Unified orchestration, guardrails | Integration and change management | Enterprise contracts |
Low‑Code Patterns (Relay + n8n + Gumloop)
Pattern A — Lead triage & instant reply
- Trigger: New form submission (Webflow/Typeform → Relay.app).
- Enrich: n8n fetches company size and tech stack via Clearbit/Crunchbase API.
- Score: LLM classifies ICP fit; Gumloop standardizes fields in a table.
- Respond: Relay.app sends email/SMS with dynamic template; human approval step for VIPs.
- Log: Push row to Google Sheets and CRM; capture latency & success flags.
Pattern B — Ticket resolution with safe actions
- Trigger: New Zendesk ticket tagged “billing”.
- Retrieve: n8n calls billing API; Gumloop parses last invoice lines into a clean table.
- Draft: LLM proposes resolution and a confirmation summary for charges/refunds.
- Approve: Relay.app asks an agent to confirm; upon yes, perform the action.
- Close: Post the final message; store trace link in the ticket.
Pattern C — Weekly knowledge refresh
- Trigger: Friday 6 pm in Relay.app.
- Collect: n8n scrapes/chats with sources; Gumloop dedupes and tags articles.
- Publish: LLM writes a short summary + source table; send review draft to Notion/Google Doc.
Example: Operator‑friendly “Router” (HTML snippet)
<details>
<summary>Router rubric (WORKFLOW vs AGENT)</summary>
<ul>
<li><strong>WORKFLOW</strong>: Steps are known; low variance; no money moved without approval.</li>
<li><strong>AGENT</strong>: Path is unclear; requires tool choice or research; confirm risky actions.</li>
<li><strong>Escalate</strong> if confidence < 0.7 or policy conflict.</li>
</ul>
</details>
RAG (only when needed)
Use RAG when tools can’t answer and policy/docs matter.
- Chunk by headings (200–600 tokens), small overlaps.
- Retrieve with hybrid search (keyword + vector). Keep k small; rerank to reduce duplicates.
- Cite exact chunks; log IDs and titles.
- Hygiene: short paragraphs, explicit dates, header rows in tables, consistent entity names.
💡 What does RAG mean? → RAG stands for Retrieval Augmented Generation. It's a technique used when tools can't answer a question and policy or documents are important.
Guardrails you should ship on day one
- Action gating: confirmation before charges, refunds, sends, and deletes.
- Policy enforcement: block disallowed domains; enforce tone and format.
- PII handling: detect, mask, and minimize; store IDs not raw text.
- Red‑team runs: re‑test after model updates. Always log why an action was blocked.
Observability and evals
Trace inputs, outputs, tool calls, retrievals, cost, and latency.
KPIs: Task success rate, first‑pass success, escalation rate (quality), tool‑call accuracy, groundedness/citation coverage, P95 latency.
Eval set: 50–100 real prompts with expected tools and blocked phrases. Run on every change.
Prompts & policies (copy‑paste example)
- You are an operations agent for <Company>.
- Do not guess. Ask for missing fields in one message.
- Use tools before stating facts when tools are authoritative.
- For charges or destructive actions: summarize and ask for confirmation.
- Always return a TRACE block with tool calls (name, args, outcome).
- If confidence < 0.7 or policy conflict: escalate to a human with context.
Style:
- Short sentences. Facts with sources. Numbered steps for instructions. If you cannot complete the task, say what is missing and give the next best step.
Six‑week rollout plan (boilerplate)
- Week 1–2: Scope jobs. Define 3–5 tools. Collect real prompts. Write a small eval set.
- Week 3: Build router + one capability agent (or Relay+n8n flow). Add guardrails and tracing.
- Week 4: Dogfood. Fix P95 latency. Raise TSR to ≥70% on your eval set.
- Week 5: Limited launch (10–20% traffic). Compare against control.
- Week 6: Full launch. Freeze prompts/policies. Version everything.
Cost & latency budgeting
Per‑task cost ≈ (system + user + retrieved tokens + tool prompts + output) × price/token.
Targets: Support/sales P95 < 6–8s; pure retrieval P95 < 3s.
Trim fat: Smaller contexts, cache tool outputs, tight top‑k, call tools only when useful.
Governance checklist
| Plan | Best For | Key Strength | Drawbacks | Pricing |
|---|---|---|---|---|
| Data classification | PII/PCI labeling | Limits exposure | Initial lift | Process time |
| Logging policy | Mask secrets | Auditability | Setup detail | Process time |
| Allow‑lists | Tools & domains | Reduces risk | Maintenance | Process time |
| Human overrides | Risky actions | Safe outcomes | Added latency | Process time |
| Safety evals | Pre/post release | Catches regressions | Ongoing work | Process time |
| Incident playbook | Rollback path | Faster recovery | Drills needed | Process time |
FAQ
How do I decide between an agent and a workflow?
Start with workflows if most tasks follow the same steps. Use agents when path choice and judgment matter.
Do I need RAG for everything?
No. Prefer tools/DBs; use RAG for the long tail; always log citations.
How many tools should an agent have?
Start with 3–5; add more when a new job demands it.
How do I keep costs predictable?
Track cost per resolved task; cache; reduce context; keep top‑k tight.
What is the fastest way to start?
Pick one high‑volume job. Define two tools. Ship one agent or a Relay+n8n flow. Trace and evaluate.
Extra resources for technical folks
Router prompt skeleton
- Classify the user’s request as WORKFLOW or AGENT.
- Return JSON: {"mode": "WORKFLOW"|"AGENT", "reason": "…"}
RAG starter settings
Chunk 300–500 tokens; overlap 50. Top‑k 4. Rerank to penalize duplicates. Prefer chunks with recent dates and explicit entities.
Evaluation metrics
A task is successful when the outcome matches the expected result, or the agent escalates with full context and a next best step. Measure FPS to reduce back‑and‑forth. Audit tool‑call accuracy and reversibility.
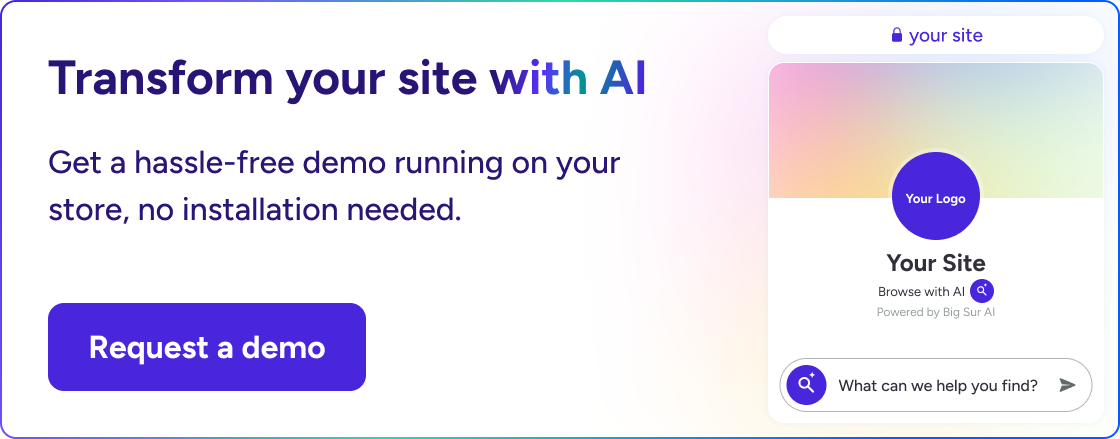
Need an AI agents that converts website visitors and can be launched in under 10 minutes?
Big Sur AI (that’s us 👋) is an AI-first chatbot assistant, personalization engine, and content marketer for websites.
Designed as AI-native from the ground up, our agents deliver deep personalization by syncing your website’s unique content and proprietary data in real time.
They interact naturally with visitors anywhere on your site, providing relevant, helpful answers that guide users toward their goals.
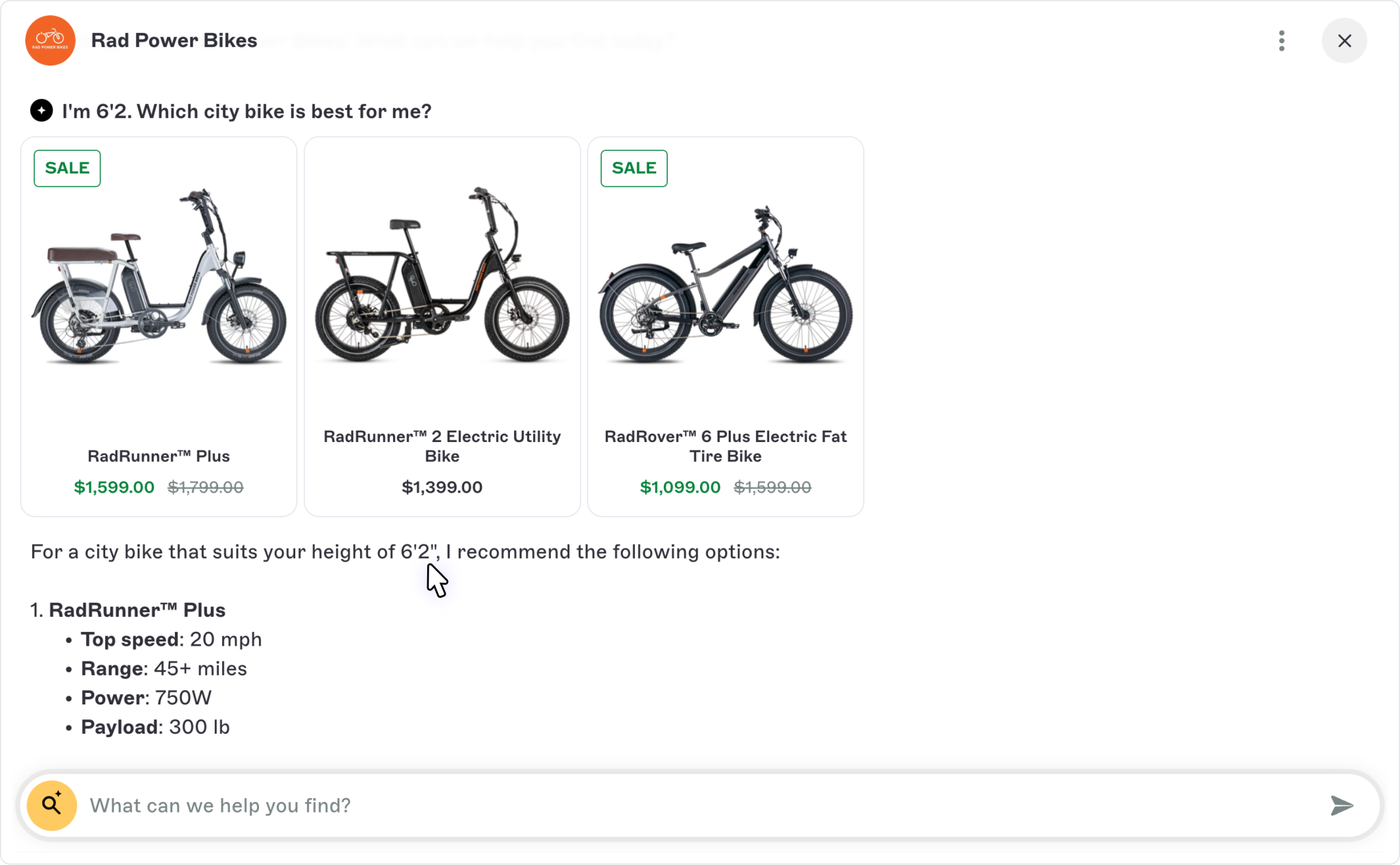
And it covers all use cases, whether that’s making a decision, finding information, or completing an action.
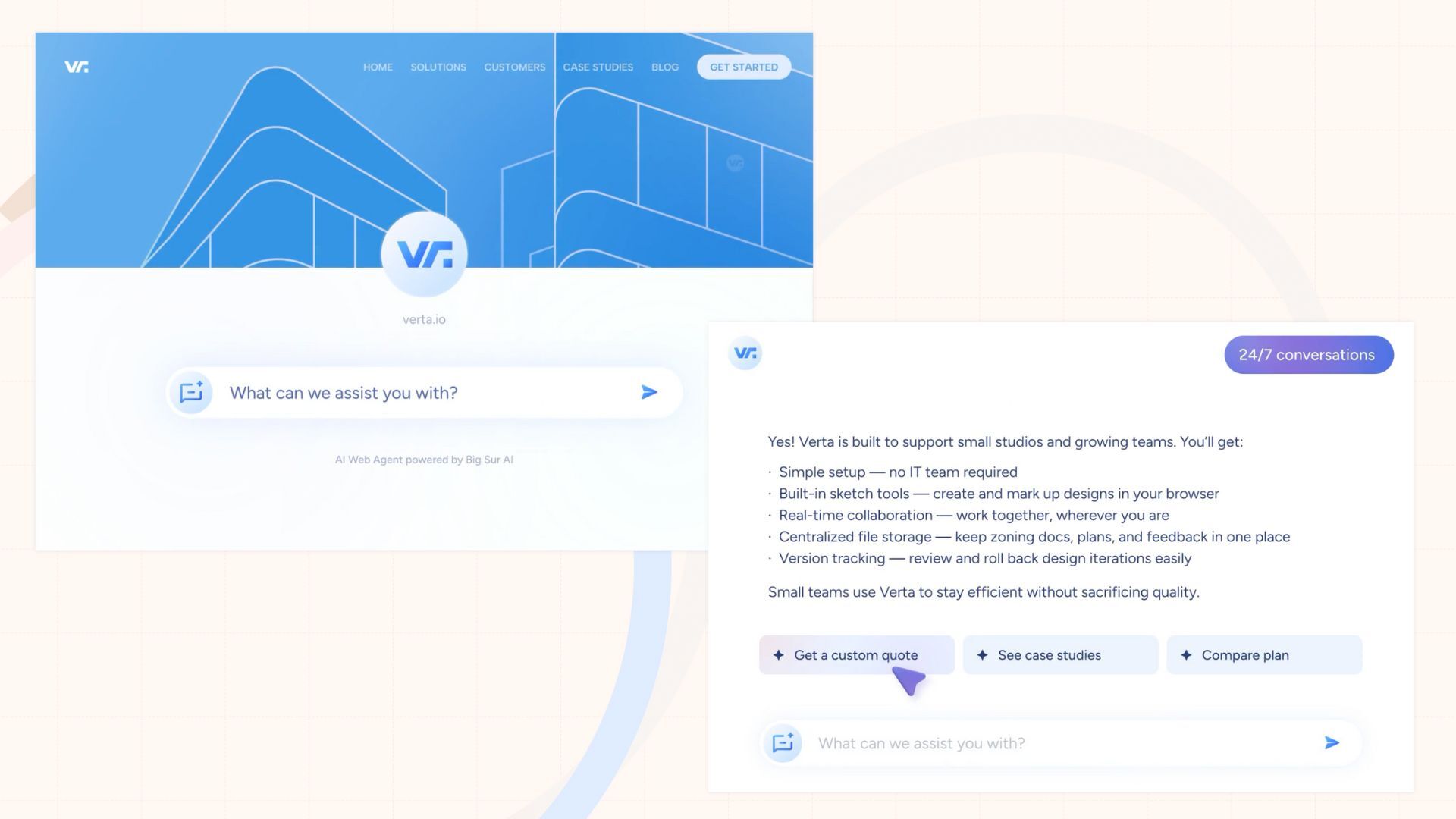
All you need to do is type in your URL, and your AI agent can be live in under 5 minutes ⤵️
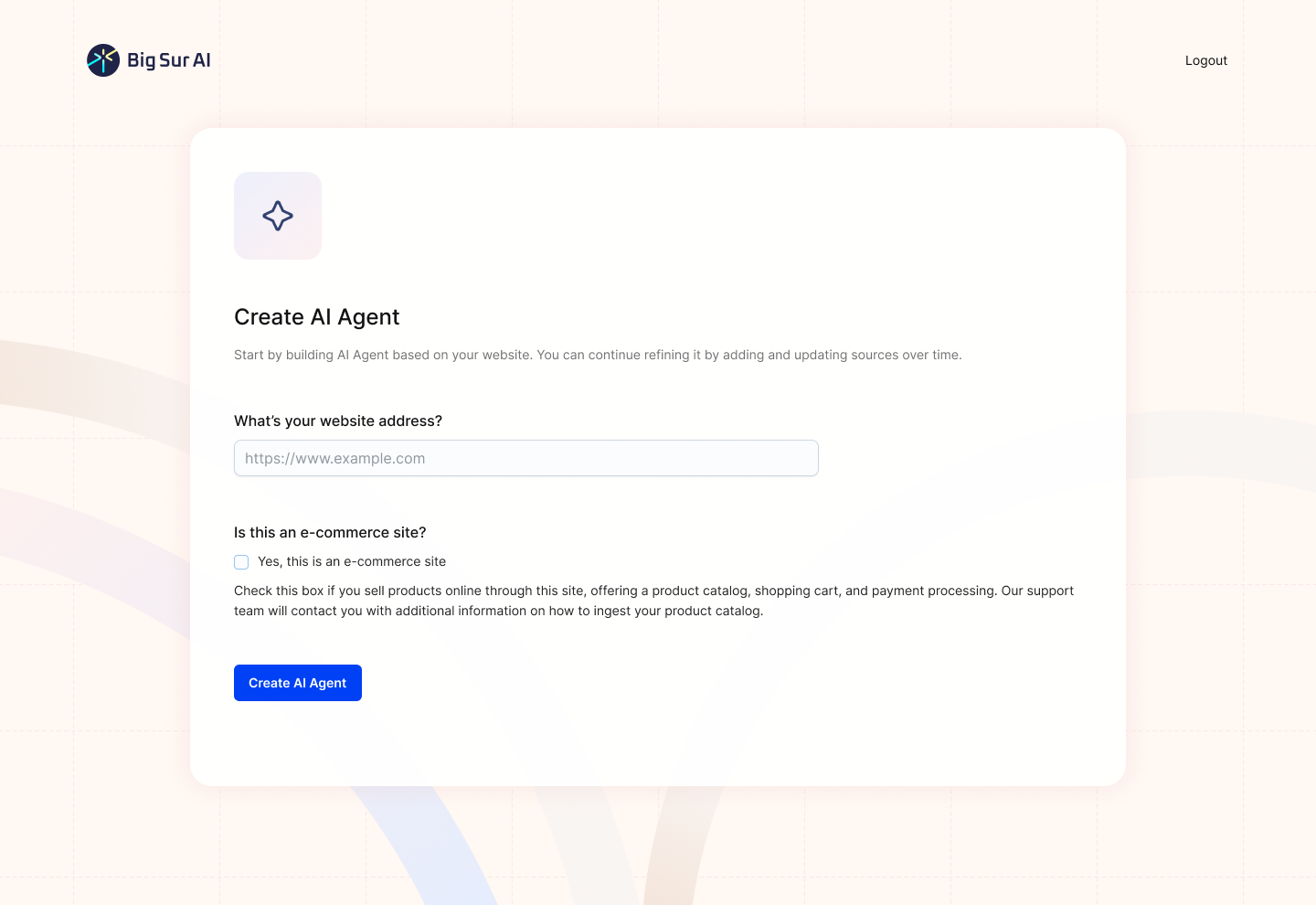
Here’s how to give it a try:
- Sign up on Big Sur AI's Hub (link here).
- Enter your website URL. Big Sur AI will automatically analyze your site content.
- Customize your AI agent. Set up specific AI actions and decide where the AI agent will appear on your site.
- Launch and monitor. Your AI agent will be live in minutes, and you can track performance with real-time analytics.